Customize Pre-packaged Server
PrimeHub provides many pre-packaged servers, it might not fit in your use cases:
You are adopting a new machine learning library, we haven't provided.
You want to support a serialization format for your model, we haven't supported it.
You want to customize monitoring metrics data.
You want to add the preprocessing or postprocessing code.
This document will show you how to customize a Python model server and focus on the model_uri mechanism of the PrimeHub Deployment. You could refer to existing implementation on the git repository primehub-seldon-servers.
We will use the code in the skeleton server to explain concepts.
How does a pre-packaged server work?
If you look at the Dockerfile in the skeleton server:
FROM python:3.7-slim
COPY ./server /app
WORKDIR /app
RUN pip install -r requirements.txt
EXPOSE 5000
EXPOSE 9000
# Define environment variable
ENV MODEL_NAME Model
ENV SERVICE_TYPE MODEL
ENV PERSISTENCE 0
CMD exec seldon-core-microservice $MODEL_NAME --service-type $SERVICE_TYPE --persistence $PERSISTENCE --access-logYou will find the entrypoint is seldon-core-microservice with a $MODEL_NAME (Model). seldon-core-microservice plays an HTTP server to get requests from clients and delegates all model requests to your Model. seldon-core-microservice will validate input data and convert it to proper data type to the Model, Model does predict and sends back results.
The main goal of building your pre-packaged server is writing your Model python module.
Model module
In our example, it defines MODEL_NAME to Model. It means that the model is a Model.py file and contains a Model class. seldon-core-microservice will load the Python module Model and get the class Model, it works in that way:
load python module Model.py
check if there is a class named Model in the loaded module.
create a Model object
The concepts of the pseudo code will look like this:
# create a user_model and delegate client calls to it
user_model = Model(**parameters)
# load model if load method implemented
user_model.load()
# response the result of the predict method
user_model.predict(features, feature_names, **kwargs)The model is a simple Python class, and you have to implement the predict to send the result of predictions:
class Model:
def __init__(self, model_uri=None):
# initialization
# 1. configure model path from the model_uri if needed
self.model_uri = model_uri
self.model = None
# 2. initialize the predictor
# you might want to enable GPU if it is not enabled automatically
# 3. invoke load method to preload the model
self.ready = False
self.load()
def load(self):
# load and create a model
# if model_uri was given, load data and create model instance from it
if self.ready:
return
# build model
# 1. set to self.model
# 2. make set.ready = True
self.ready = True
def predict(self, X, feature_names = None, meta = None):
# execute self.model.predict(X)
print(X, feature_names, meta)
return "Hello Model"Handle model files
The model files could ship along with your image or can be downloaded until the model server starts. To download the file at startup, PrimeHub users could create a Deployment with Model URI:
PrimeHub users could create a Deployment with Model URI:
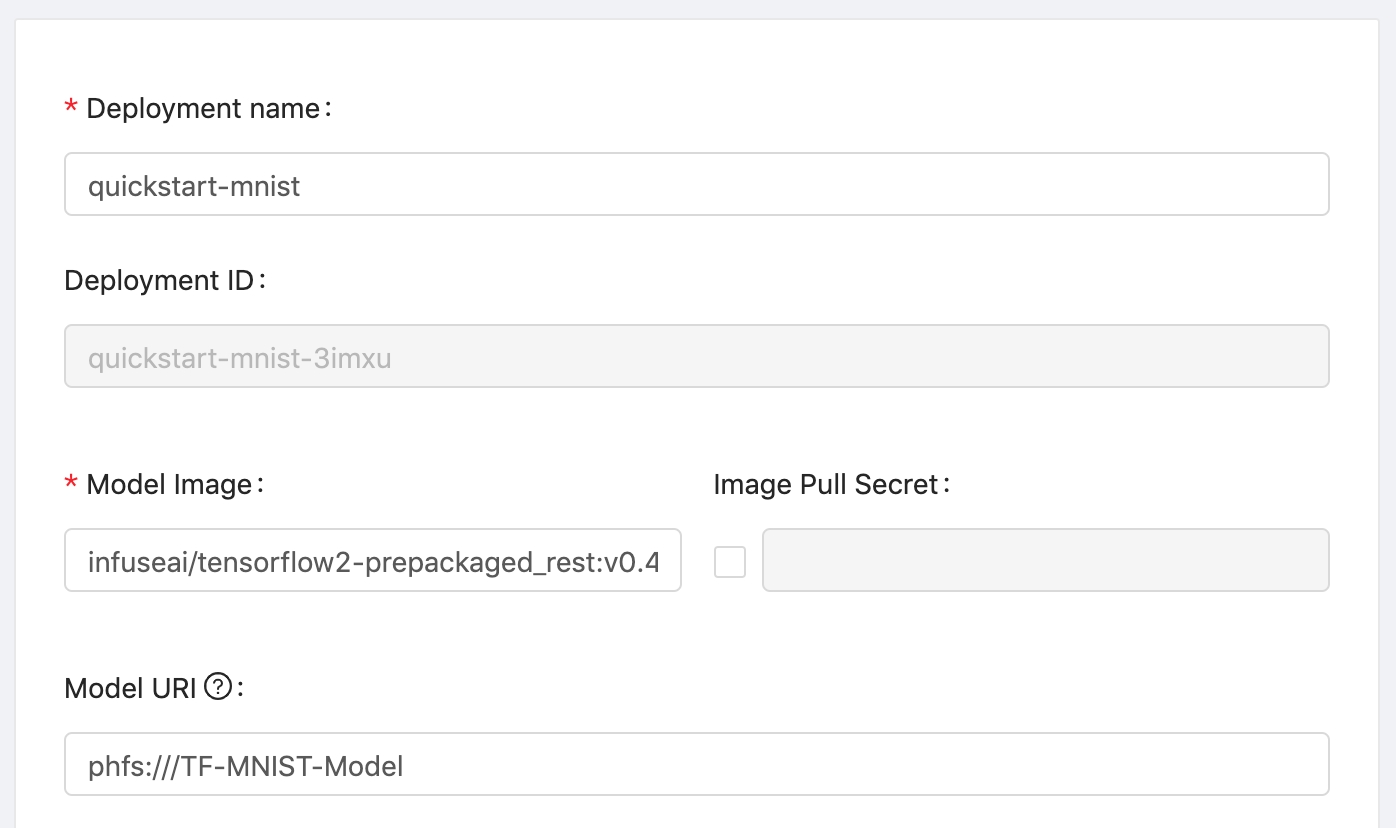
In the container's view, the model files will mount to a local filesystem, such as /mnt/models:
def __init__(self, model_uri=None):
self.model_uri = model_uri
...Please add the model_uri argument to the __init__ function and make sure to have None as the default value. It means your Model supporting with or without model_uri. If a user gives a Model URI value, the __init__ will get a mount path from the variable model_uri. You can check which files should be loaded in that path.
It is very common to write a load method to load and build model instance:
def load(self):
...You could build the model instance in the __init__, if your loading process is very simple. The load method is optional.
You might check Model URI to learn about it.